What Are Transformer Models and How Do They Work?
About
What Are Transformer Models and How Do They Work? ATTACH
Command: Write a story. Response: Once
Next command: Write a story. Once Response: upon
Next command: Write a story. Once upon Response: a
Next command: Write a story. Once upon a Response: time
Next command: Write a story. Once upon a time Response: there
etc.
The transformer has 4 main parts:
- Tokenization
- Embedding
- Positional encoding
- Transformer block (several of these)
- Softmax
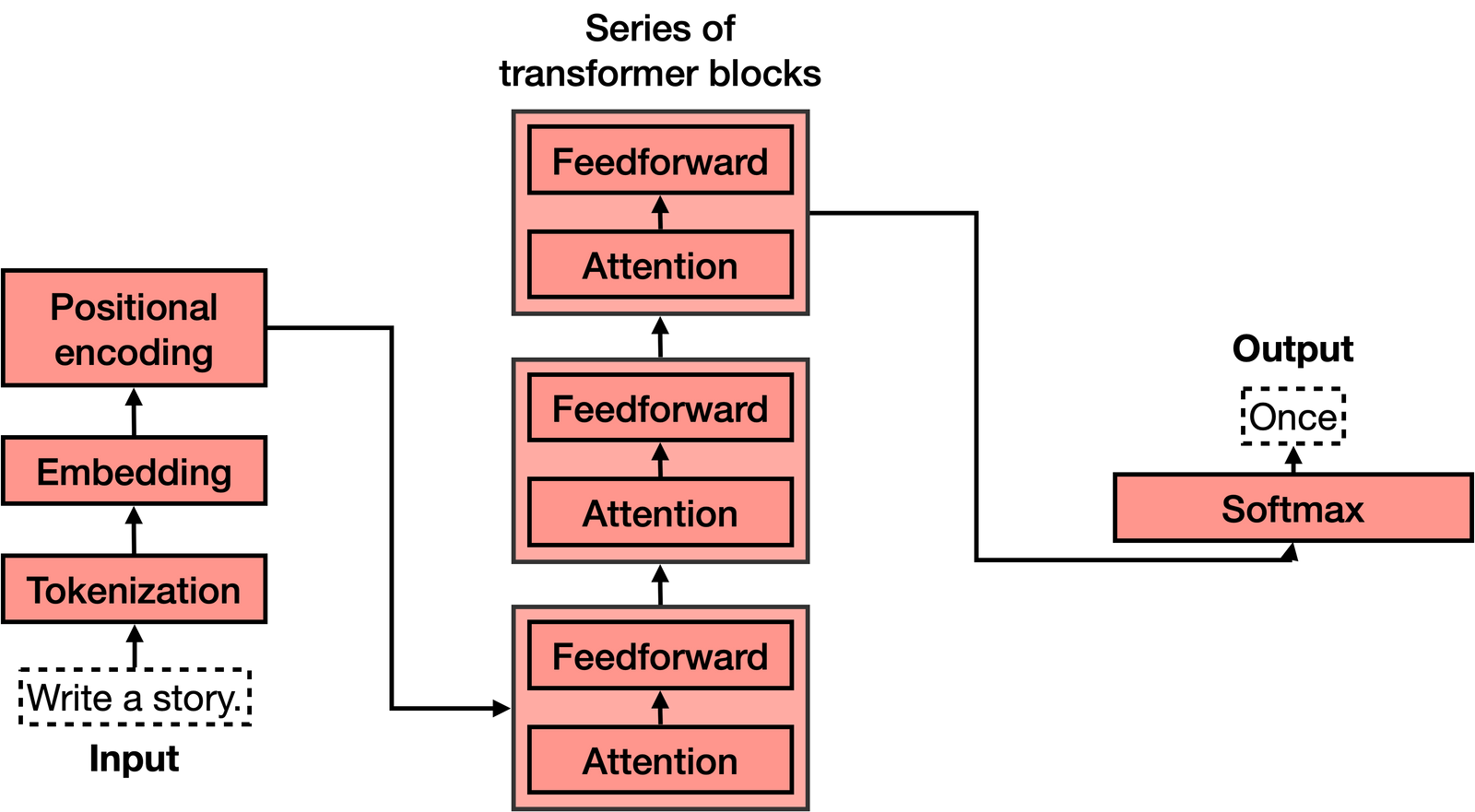
Tokenization ATTACH
Tokenization is the most basic step. It consists of a large dataset of tokens, including all the words, punctuation signs, etc. The tokenization step takes every word, prefix, suffix, and punctuation signs, and sends them to a known token from the library.

Embedding ATTACH
Once the input has been tokenized, it’s time to turn words into numbers. Embeddings…is the bridge that turns text into numbers. As humans are good with text, and computers with numbers, the stronger this bridge is, the more powerful language models can be.
In short, text embeddings send every piece of text to a vector (a list) of numbers. If two pieces of text are similar, then the numbers in their corresponding vectors are similar to each other (componentwise, meaning each pair of numbers in the same position are similar). Otherwise, if two pieces of text are different, then the numbers in their corresponding vectors are different.
For example, in the embedding below, the coordinates for cherry are [6,4], which are close to strawberry [5,4], but far from castle [1,2].

in the case of transformers, we’ll be using a word embedding, meaning that every word in the sentence gets sent to a corresponding vector. For example, if the sentence we are considering is “Write a story.” and the tokens are <Write>, <a>, <story>, and <.>, then each one of these will be sent to a long vector, and we’ll have four vectors.

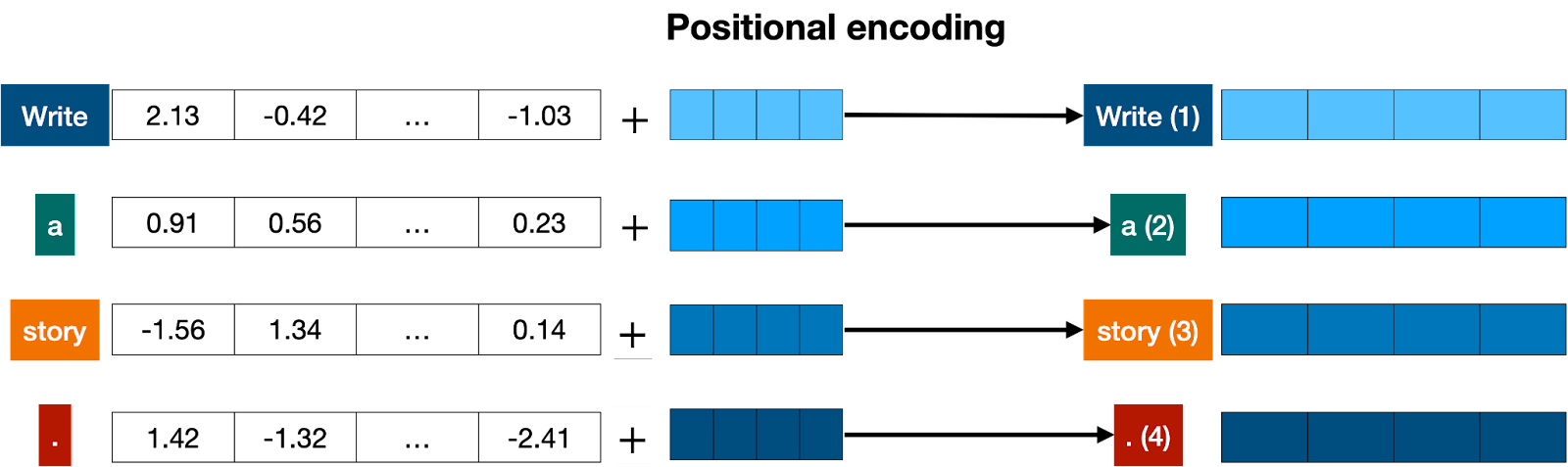
Positional encoding ATTACH
Positional encoding consists of adding a sequence of predefined vectors to the embedding vectors of the words. This ensures we get a unique vector for every sentence, and sentences with the same words in different order will be assigned different vectors. In the example below, the vectors corresponding to the words “Write”, “a”, “story”, and “.” become the modified vectors that carry information about their position, labeled “Write (1)”, “a (2)”, “story (3)”, and “. (4)”.
Transformer block
the next step is to predict the next word in this sentence.
We can train such a large network, but we can vastly improve it by adding a key step: the attention component. Introduced in the seminal paper Attention is All you Need, it is one of the key ingredients in transformer models, and one of the reasons they work so well.
The attention component is added at every block of the feedforward network. Therefore, if you imagine a large feedforward neural network whose goal is to predict the next word, formed by several blocks of smaller neural networks, an attention component is added to each one of these blocks. Each component of the transformer, called a transformer block, is then formed by two main components:
- The attention component.
- The feedforward component.
Attention ATTACH
The attention step deals with…the problem of context. two sentences:
- Sentence 1: The bank of the river.
- Sentence 2: Money in the bank.
‘bank’ appears in both, but with different definitions…computer has no idea of this…For the first sentence, the words ‘the’, and ‘of’ do us no good. But the word ‘river’ is the one that is letting us know that we’re talking about the land at the side of the river. Similarly, in sentence 2, the word ‘money’ is the one that is helping us understand that the word ‘bank’ is now referring to the institution that holds money.

what attention does is it moves the words in a sentence (or piece of text) closer in the word embedding. In that way, the word “bank” in the sentence “Money in the bank” will be moved closer to the word “money”. Equivalently, in the sentence “The bank of the river”, the word “bank” will be moved closer to the word “river”. That way, the modified word “bank” in each of the two sentences will carry some of the information of the neighboring words, adding context to it.
attention in transformer…called multi-head attention.In multi-head attention, several different embeddings are used to modify the vectors and add context to them.
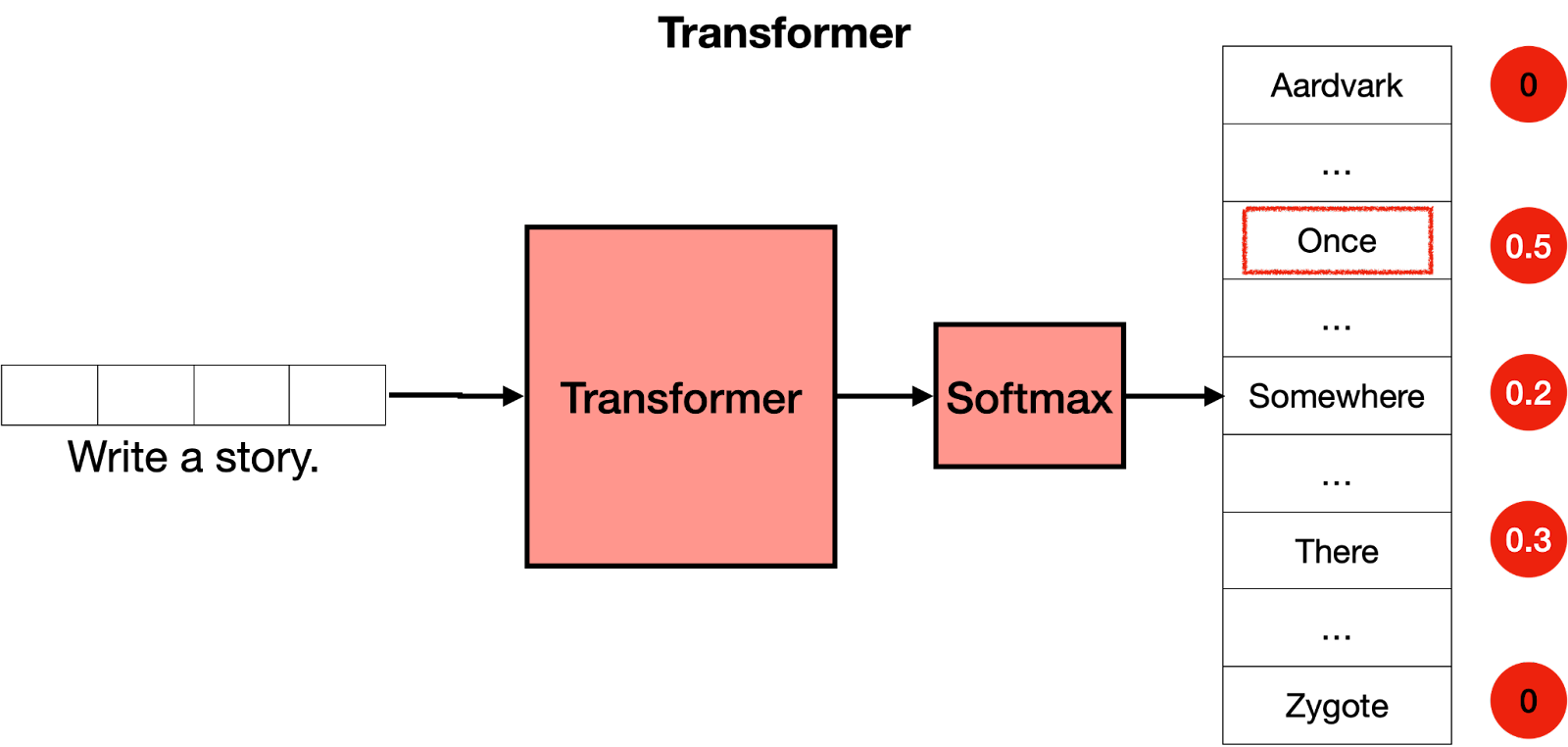
The Softmax Layer ATTACH
The last step of a transformer is a softmax layer, which turns these scores into probabilities (that add to 1), where the highest scores correspond to the highest probabilities. Then, we can sample out of these probabilities for the next word. In the example below, the transformer gives the highest probability of 0.5 to “Once”, and probabilities of 0.3 and 0.2 to “Somewhere” and “There”. Once we sample, the word “once” is selected, and that’s the output of the transformer
 Now what? Well, we repeat the step. We now input the text “Write a story. Once” into the model, and most likely, the output will be “upon”. Repeating this step again and again, the transformer will end up writing a story, such as “Once upon a time, there was a …”.
Now what? Well, we repeat the step. We now input the text “Write a story. Once” into the model, and most likely, the output will be “upon”. Repeating this step again and again, the transformer will end up writing a story, such as “Once upon a time, there was a …”.
Post Training
Imagine the following: You as the transformer “What is the capital of Algeria?”. We would love for it to answer “Algiers”, and move on. how do we get the transformer to answer questions?
The answer is post-training. In the same way that you would teach a person to do certain tasks, you can get a transformer to perform tasks. Once a transformer is trained on the entire internet, then it is trained again on a large dataset which corresponds to lots of questions and their respective answers. Transformers (like humans), have a bias towards the last things they’ve learned, so post-training has proven a very useful step to help transformers succeed at the tasks they are asked to.